Detection challenge
Represent faults that are clear threshold breaches, such as leak-check flow, and faults that are mainly multivariate drift, such as pressure sensor bias or propellant slosh.
Project Case Study
A synthetic spacecraft telemetry system for testing hybrid anomaly monitoring and grounded LLM explanations across mission phases.
Autonomous propellant transfer is a useful monitoring problem because several subsystems move at the same time: robotic alignment, docking loads, seal pressure, transfer pressure, flow rate, pump behavior, thermal state, and spacecraft attitude. Some faults are obvious threshold violations. Others only look suspicious when multiple signals drift together.
I built this project around that split. The simulator generates a complete 410-second refueling mission, deterministic rules own the hard-limit safety checks, and a phase-aware anomaly detector provides advisory scoring for multivariate drift. I then added RefuelGuard-LM, a fine-tuned explainer layer that turns grounded rule, score, and attribution outputs into concise operator-facing explanations. The result is a small but complete telemetry pipeline with scenario generation, scoring, attribution, LLM fine-tuning, regression tests, and model cards that clearly state the limits of synthetic evaluation.
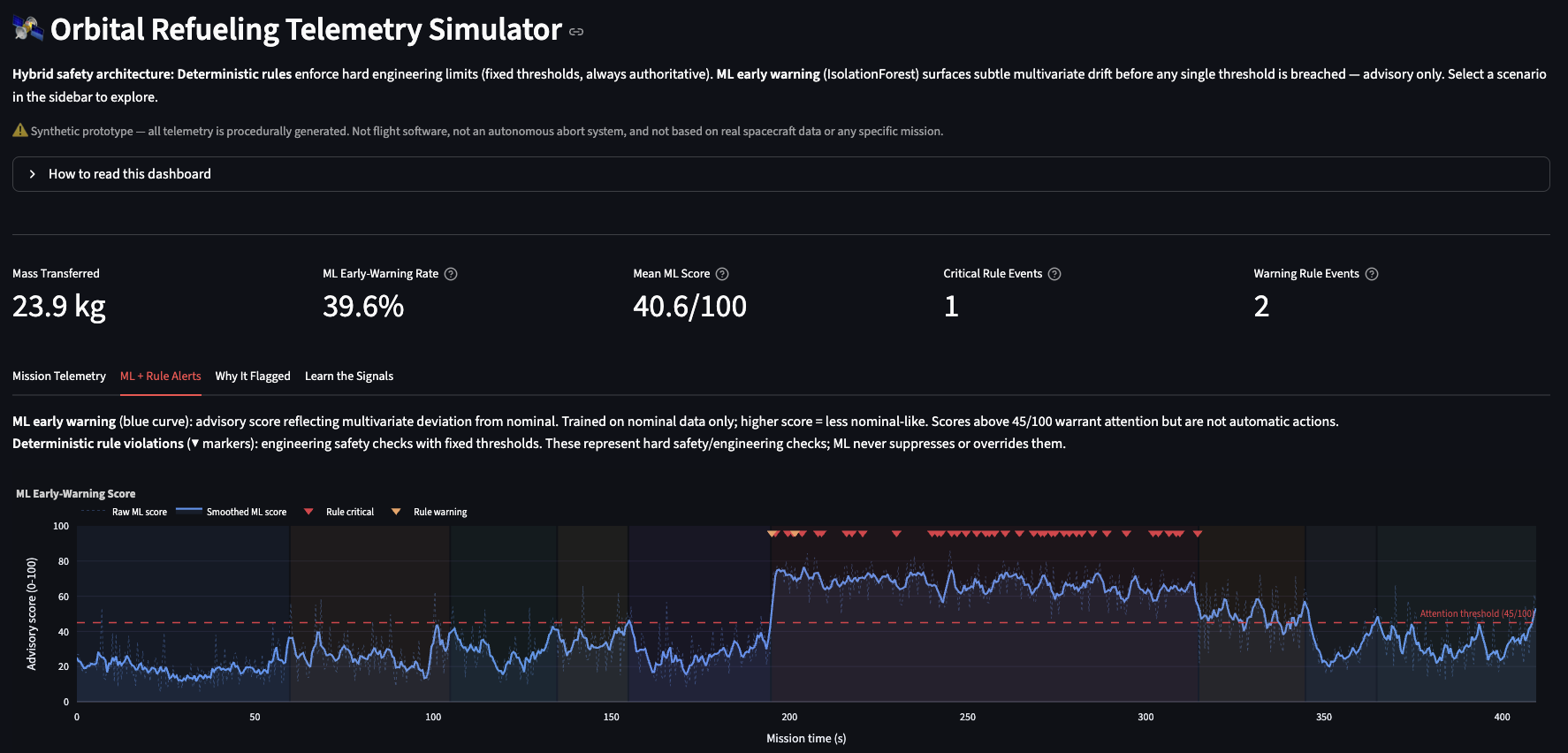
A single anomaly detector is the wrong mental model for this domain. During approach, zero propellant flow is normal. During main transfer, zero flow is suspicious. A pressure value that looks reasonable in one phase can be wrong in another. The monitoring system needs phase context before it can decide whether telemetry is nominal.
The other constraint is authority. If bus voltage drops too low, pump current spikes, or seal pressure falls after the seal is established, a deterministic rule should fire regardless of what an ML model thinks. The model can help surface softer patterns, but it should not override hard engineering checks.
Represent faults that are clear threshold breaches, such as leak-check flow, and faults that are mainly multivariate drift, such as pressure sensor bias or propellant slosh.
Keep deterministic safety rules independent from ML scoring. Rules make explicit engineering checks; ML provides advisory pattern recognition and supporting evidence.
The core of the project is simulator.py. It creates a
reproducible mission timeline with phase-specific nominal behavior, then injects scenario
anomalies at the operational phase where they make sense.
I split monitoring into two independent layers so the behavior is easier to reason about and safer to explain.
rules.py defines explicit warning and critical thresholds for attitude error,
bus voltage, seal pressure, leak-check flow, line pressure, pump current, interface force,
and arm position. Rules can be scoped to phases so expected ramps do not create false
alerts.
Raw timestamp-level alerts are grouped into event windows by rule and phase. This prevents oscillating signals from flooding the operator view with dozens of nearly identical rows.
detector.py trains one IsolationForest per phase on nominal telemetry. At
inference time, each row is scored against the model for its current phase instead of a
global baseline.
The detector maps threshold-relative IsolationForest outputs into a 0 to 1 anomaly score with a sigmoid transform. The score is useful for ranking and inspection, not as a calibrated probability.
Because this is a monitoring system, a high score by itself is not enough. The project includes lightweight attribution, an optional fine-tuned explanation model, and a repeatable validation script so each scenario has inspectable evidence.
explainer.py
replaces each feature with that phase's nominal mean and measures how much the anomaly score
drops. Large drops identify the signals pushing the score upward.scripts/validate_scenarios.py trains or loads
the default detector, evaluates every scenario, and writes a compact CSV with max score, mean
score, anomaly rate, rule alert counts, highest severity, and top contributing signal.MODEL_CARD.md and the RefuelGuard-LM model card
document training data, intended use, score interpretation, limitations, and the validation
needed before anything like this could be considered for real telemetry.RefuelGuard-LM is an optional research extension under llm/.
It fine-tunes a small open-source instruction model to explain synthetic telemetry anomalies
from structured monitoring outputs rather than raw, unconstrained prompts.
The prompt payload includes mission phase, scenario context, deterministic rule alerts, advisory ML score, top attribution signals, and current telemetry values. The LLM does not detect anomalies or set alert severity.
llm/data/generate_instruction_data.py creates deterministic JSONL examples for
explanation, classification, attribution, rule-vs-ML distinction, and uncertainty wording
tasks.
The training path uses Hugging Face Transformers and PEFT to tune a Qwen2.5-0.5B-Instruct adapter, with optional 4-bit loading for constrained GPU environments.
On 100 held-out synthetic examples, the fine-tuned adapter scored 4.86 out of 5 on a deterministic rubric, compared with 3.69 out of 5 for the base model.
The validation story is designed to show why both monitoring layers exist. Some injected faults trigger explicit rules. Others stay under hard thresholds but still look unusual to the phase-aware detector.
Key pattern: partial blockage triggers both deterministic pressure/current rules and elevated ML scores, while sensor drift and unstable slosh can raise ML anomaly rates without grouped rule alerts. That is the architectural point of the project.
The baseline stays quiet, with no grouped rule alerts and low average anomaly scoring. This gives the validation script a stable control case.
Flow drops while line pressure and pump current rise, so both the rule engine and ML detector have reason to flag the scenario.
Pressure readings drift upward over the mission. The model sees the pattern, but hard rules can remain quiet because no explicit threshold is crossed.
Flow, line pressure, and propellant temperature oscillate together during transfer, making the drift multivariate rather than a single obvious hard-limit breach.
The strongest part of the project is not the dashboard. It is the system boundary between simulation, rule authority, advisory ML, explanation, and validation.
This is an educational prototype. It is not flight software, not an autonomous abort system, and not based on real spacecraft telemetry. The important engineering habit here is being explicit about those boundaries.